Weighted Hegselmann-Krause
The WHK (Weighted Hegselmann-Krause) model [1] extends the classical HK model by introducing a weight parameter \(w\) that controls the influence strength of \(\varepsilon\)-neighbors. Each node holds an initial opinion \(h \in [-1,1]\) and updates it in discrete rounds. At each step: 1) \(\varepsilon\)-neighbor identification: find the set \(\Gamma_\varepsilon\) of each node, \(d_{i,j}=\left|h_i-h_j\right|\le\varepsilon\), \(j\in\Gamma_\varepsilon\); 2) update the opinion value: The opinion of node \(i\) at the next time step is updated as follows:
where \(\#\Gamma_\varepsilon\) denotes the number of \(\varepsilon\)-neighbors, and \(w_{ij}\) is the influence weight of edge \((i,j)\in E\). The factor \((1-|h_i^{(k-1)}|)\) ensures that opinions remain bounded in \([-1,1]\) and that opinions closer to the extremes are harder to shift.
Implementation
The WHK model extends the HK model by (i) weighting the neighbor average with a parameter \(w_{ij}\) and (ii) applying a bounded update rule that keeps opinions within \([-1,1]\). Similar to HK, if \(\#\Gamma_\varepsilon=0\), the opinion remains unchanged; otherwise it is updated via the weighted aggregation.
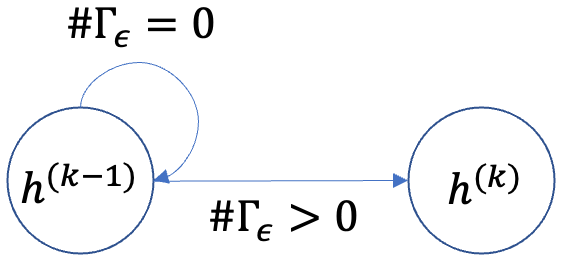
For each neighbor \(j \in N(i)\), generate two message terms:
where \(\mathbf{1}(\cdot)\) is the indicator function and \(w_{ij}\) is the influence weight of edge \((i,j)\in E\).
Node \(i\) aggregates received messages by computing the weighted average of \(\varepsilon\)-neighbors:
Finally, the opinion of node \(i\) is updated with the bounded update rule:
The factor \((1 - |h_i^{(k-1)}|)\) acts as a damping term: nodes with opinions close to the boundary values \(\pm 1\) receive smaller updates, naturally preventing the opinion from exceeding the valid range.
Status
During the simulation, a node holds a continuous opinion value:
Status |
Range |
|---|---|
Opinion |
Float in [-1,1] |
WHKModel
- class fs_gplib.Opinions.WHKModel.WHKModel(data, seeds, epsilon, weight, device='cpu', rand_seed=None)[source]
Bases:
DiffusionModelWeighted Hegselmann-Krause (WHK) bounded-confidence opinion dynamics on static graphs.
Like the classical HK model, each node has a continuous opinion in \((-1, 1)\) (initialised from seeds or sampled uniformly when seeds is
None). Neighbors \(j\) with \(|h_i^{(k-1)} - h_j^{(k-1)}| < \varepsilon\) contribute to a weighted average \(m_i^{(k)}\) where edge weights \(w_{ij}\) scale each neighbor term. If no such neighbor exists, the opinion is unchanged; otherwise \(h_i^{(k)} = h_i^{(k-1)} + m_i^{(k)} (1 - |h_i^{(k-1)}|)\), so opinions stay bounded and moves near \(\pm 1\) are damped. Self-loops are removed from the edge index.- Parameters:
data (torch_geometric.data.Data) -- PyTorch Geometric
Datarepresenting \(G=(V,E)\). Must provideedge_indexandnum_nodes.seeds (list[float] | None) -- Initial opinion per node, length
num_nodes, each strictly between-1and1; orNoneto sample each component independently from \(\mathrm{Uniform}(-1, 1)\) (using rand_seed for the RNG).epsilon (float) -- Confidence bound \(\varepsilon\) in
[0, 1]; only neighbors with opinion separation below this threshold contribute.weight (float | list[float]) -- Global scalar in
(0, 1)applied to every edge message, or a list of floats strictly in(0, 1)for per-node weights (broadcast in message passing), as in the reference documentation.device (str | int) -- (optional)
'cpu'or a CUDA device index. Defaults to'cpu'.rand_seed (int | None) -- (optional) Seed for the random number generator when seeds is
None. Defaults toNone.
- run_iteration()[source]
Execute a single opinion-update step.
The internal
node_statusis updated so that subsequent calls continue from the latest opinion configuration.- Returns:
Node opinions after one step, shape
(1, N).- Return type:
torch.Tensor
- run_iterations(times)[source]
Execute times opinion-update steps sequentially.
The internal
node_statusis updated in-place so that subsequent calls continue from the latest opinion configuration.- Parameters:
times (int) -- Number of steps to run.
- Returns:
Node opinions at final step, shape
(1, N).- Return type:
torch.Tensor
- run_epoch(iterations_times)[source]
Run a single Monte-Carlo epoch (one independent realisation).
Node opinions are re-initialised before the epoch starts.
- Parameters:
iterations_times (int) -- Number of opinion-update steps per epoch.
- Returns:
Node opinions at final step of the epoch, shape
(1, N).- Return type:
torch.Tensor
- run_epochs(epochs, iterations_times, batch_size=200)[source]
Run multiple independent Monte-Carlo epochs in batches.
Node opinions are re-initialised before the run.
- Parameters:
epochs (int) -- Total number of independent realisations.
iterations_times (int) -- Number of opinion-update steps per epoch.
batch_size (int) -- (optional) Number of epochs processed in parallel per batch. Defaults to
200.
- Returns:
Node opinions at final step of all epochs, shape
(epochs, N).- Return type:
torch.Tensor
Parameters
Name |
Type |
Default |
Required |
Description |
|---|---|---|---|---|
data |
Data |
Yes |
Data of graph. |
|
seeds |
List[float] / None |
Yes |
List of initial opinion values or None to generate randomly. |
|
epsilon |
float in [0, 1] |
Yes |
Confidence bound determining which neighbors influence the opinion update. |
|
weight |
float in [0, 1] / List[float] |
Yes |
Influence weight applied to the neighbor average. Scalar for global weight, or list of per-node weights. |
|
device |
'cpu'/int (CUDA index) |
'cpu' |
No |
Device to run the model on. |
rand_seed |
Int |
None |
No |
Random seed for generating the initial opinion values. |